How dirty is your context window?
你的 token 消耗 99% 以上都在 input——因为你的 context window 太脏了。旧上下文、重复搜索、过期内容,每一轮都被重新喂进去。
99.7% 的钱花在 input 上
我第一次认真意识到 context window 有多浪费,是因为 Reddit 用户 karmendra_choudhary 的一条帖子。作者统计了自己在 Claude Code 里的 100M token:99.4% 都是 input。也就是说,钱大部分不是花在模型写代码上,而是花在每一轮把旧上下文重新喂进去。
我一开始不太信,于是抓了一条自己的 Codex coding session 来拆。结果更夸张:这条 session 总共消耗 10.9M token,99.7% 是 input,真正写出去的 output 只有 25.8K。
后来我把范围放大到能核对的 Codex 历史:69 个 session,总计 1.70B token,按 API 价格估算约 $1.47K。里面 99.7% 是 input,94% 的 input 是 cached input,也就是每一轮反复带回模型的旧上下文。output 只值约 $167。
这就不是“某一次对话很贵”了,而是 agentic coding 的默认姿势:模型每写一点东西,都要先吞下一大坨历史。
所以我真正想问的不是:为什么 AI 写代码这么贵?而是:这些被反复喂进去的 context,到底还有多少真的有用?
先把一次工作拆开
一个 working session,就是一段为了把代码改到可落地点的对话。
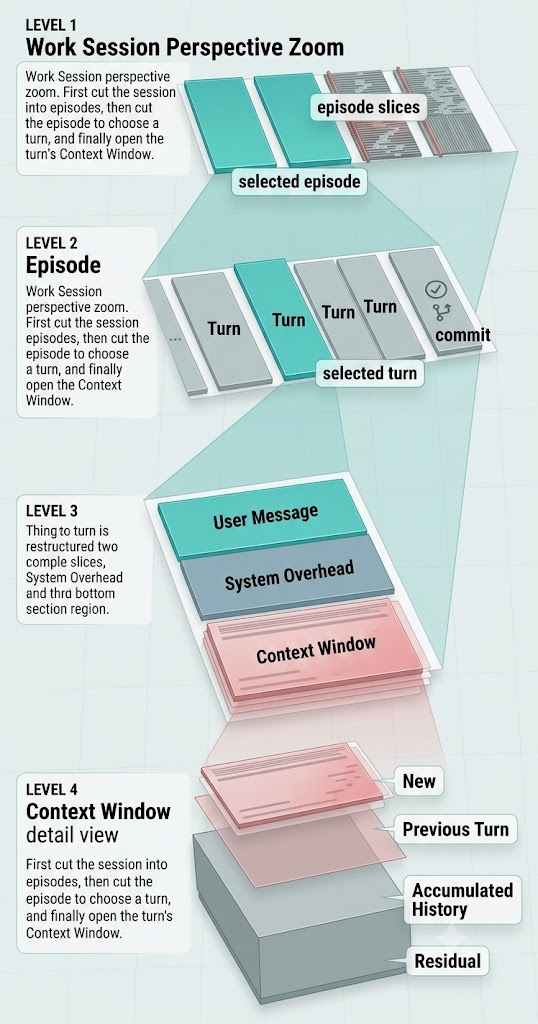
所以 commit 是一个很自然的边界。一次有效 commit,说明前面那段工作真的完成了一个小任务。
但一个 commit 往往不是一轮就做完的。它通常需要好几个 turn:我提要求,它读文件,它改代码,我纠正,它再改,最后 commit。我把这一小段叫一个 episode。
一个 session 里可以有多个 episode。多少取决于你的习惯:有人一个 session 只做一件事,有人一路聊下去,做完好几个 commit。
episode 里还有 turn。每个 turn 都会带着一个 context window:系统提示、历史对话、读过的文件、工具输出、刚刚改过的代码,全都塞在里面。
这样拆开以后,一个 commit 真正需要什么、又被迫背上了多少旧东西,就能直接看见。
A typical session tells everything
我是个 agentic builder,日常三件套:Codex、Claude Code、OpenClaw。活儿主要是网站和一些应用:前端页面、组件、动画、上线修 bug,都是这种。
光看 Codex:从 4 月 25 号 到现在,我攒了 120 个 session,光 6 月就有 69 个。我挑了 6 月 2 号 那条,不是因为它极端,而是因为它太像日常工作。
那天我在重做 Echo 官网首页:改排版、补几个卖点模块、接一个吉祥物 loading 动画。不是 benchmark,不是 demo,就是一个中等难度的前端任务。
这条 session 有 70 个 turn,最后落了 7 次 commit。我平时就是这么干活:先说目标,让 agent 读文件、改代码、看效果,再一点点纠正,能落地就 commit。
所以它典型:任务不大,流程真实,节奏也像大多数 agentic coding。真正不典型的是代价:这样一个首页改动,最后吞了 10.9M token。
最后产物并不重:几个文件的 diff,KB 级。工作方式也不稀奇:几轮探索、几轮修改、几轮确认。就是这样一个常规任务,把问题暴露得很干净。
我要扒开看的,就是这一个。普通,所以值得看,因为你的每一个 session,大概都长这样。
把镜头推到最后三轮
这条 working session 一共有 70 个 turn,落了 7 次 commit。不用把 70 轮全讲完,先看图右端的三轮:T65、T66、T67。
这里的位置很关键:T65 刚落下第 6 个 commit,T66 和 T67 马上又把窗口顶回高位,后面还有 T70 这个最终 commit。也就是说,我们看的不是平均值,而是一次真实 session 右端的局部。
问题也在这里冒出来:T65 已经接近饱和,T66 直接涨到 220.2K token,T67 没有变小。三轮平均下来,真正有用的部分只有 23.5%,剩下 76.5% 是噪音、重复、过期历史。
22.9% useful · 77.1% noise
20.1% useful · 79.9% noise
27.3% useful · 72.7% noise
最刺眼的是 T67。我只补了一句:你不该把那个受保护的 v21 改成普通 public。但这一句仍然带着 220.2K context 进模型。
新指令很短,旧窗口很大。慢、贵、容易乱改,不是因为任务特殊,而是因为每一个小修复都在背着一整段旧现场往前走。
T67 的 220K 是一整段执行记录
T67 不是一条新消息单独进模型。它进来时,Codex runtime 会重新组装一次 model-call input:系统提示、工具协议、历史对话、前面读过的文件、搜索结果、命令输出、diff、错误日志、截图说明,都会一起带上。
所以 T67 的 220.2K token,不是我那一句话本身。它更像一个执行现场的快照。
先看一个更早的 turn。T30 只有 179.0K,还没有到 T67 的 220.2K,但结构已经长出来了:真正承重的代码和指令只是一部分,更多体积来自系统外壳、重新定位、旧 diff、重复文件快照和已经翻篇的输出。
系统和工具外壳
约 13.9K。包括 system message、工具 schema、调用格式、序列化开销。这部分每轮都要垫底。
当前产品代码
约 46.1K。包括正在改的页面、组件、Rive loading 相关代码,以及刚刚形成的 diff。
工具调用输出
最大的一块,接近 99.2K。里面有 rg、文件读取、目录查看、git 状态、报错日志、重新定位路径这些执行痕迹。
重复文件快照
约 21.5K。同一个文件、同一段代码,被不同 turn 读进来以后,旧版本还留在窗口里。
更早的会话残留
约 39.6K。前面做首页、模块、样式、动画时留下的旧上下文,还跟着最后这个 episode 一起走。
用户新输入
很小。T67 我只是在纠正方向:不要把受保护的 v21 当成普通 public。
从 T65 到 T66,窗口从 182.1K 跳到 220.2K,多出来 38.1K。主要不是新代码,而是为了定位问题产生的读取、搜索、命令输出和旧历史。
到 T67,总量没有变,还是 220.2K。但里面的结构变了:当前产品代码从 30.5K 涨到 46.1K,重复文件快照也从 17.6K 涨到 21.5K。也就是说,模型更接近真正要改的地方了,但它没有放下前面背着的现场。
这就是为什么一个很短的纠正,也会带着二十多万 token 进模型。它不是在读一句话,它是在重放一段工作过程。
T67 的 context window,不是干净记忆,是一份很厚的执行记录。
为什么必然是这样
这不是某个 agent 写得差,而是 runtime 的工作方式决定的。
Codex 官方文档里说得很直:一个 thread 里会有你的 prompt、model outputs、tool calls。agent 工作时,还会继续收集 file contents、tool output,以及它做过什么、接下来要做什么的 ongoing record。所有这些东西,都必须塞进下一次 model call 的 context window。
在我们的 70-turn session 里,它主要有三种模式:多数时候 copy-forward + append,把旧记录带到下一轮;窗口吃紧时做 oldest-edge truncation,从边缘丢掉一部分;撑到阈值时触发 compaction,把一段历史改写成摘要。它不是记忆系统,只是在上下文限制里搬运、截断、改写执行记录。
所以窗口必然会大。只要一个 episode 需要多轮文件读取、搜索、改代码、看 diff、跑验证,context 就会从几十 K 涨到二十多万 K。哪怕最后用户只补一句话,模型也要先吞下这整段工作现场。
更麻烦的是,变大不只是贵。Chroma 那篇 Context Rot 里讲过一个基本现象:模型并不会均匀地使用长上下文,输入越长,表现越不稳定。放到 coding agent 里,就是旧文件版本、过期 diff、命令输出、搜索残留会和当前任务信号混在一起。
结果不是模型一定失败,而是准确度变脆:它更容易抓错版本、相信旧路径、沿着上一次搜索的方向继续走。最后还是能成功,但要更多 turn、更多 token、更多纠正。
它必然很大,而且越大越容易稀释真正该看的东西。
拿 commit 当尺子:这 22 万里,七成跟结果无关
“长”本身不是病根。同样是 22 万,如果每一条都跟这一刻要做的事相关,它不会乱。问题是,大多数都不相关。
commit 是最硬的尺子。
这一段的结果,就是最后那次 commit:把受保护的动画弄上线,改了 4 个文件,几 KB 的 diff。那就是“有用”的全部定义。进了这次 commit 的,有用;没进的,都是为了走到这一步、留在路上的脚印。
拿这把尺子量 T67 的 220.2K,用一个偏宽的口径数,把所有重新翻找、重复读、过期内容都算成脚印:真正承重的,大概 27%,系统脚手架 6%,加此刻正在改的那几个文件的现版 21%。剩下七成多,全是脚印。
那七成,主要长这样:
5 万的检索。为了找文件跑的 rg、grep。找到了,事就完了;日志还一直躺在窗口里。
4 万的命令输出。git diff、build、curl,全是查那个 bug 时的诊断。bug 查完了,输出没用了,没人收走。
89 次 page.jsx。commit 只要最后一版,前面 88 次重读,全是路上的影子。
一张 32K 截图、一堆过期 diff。更早某一轮要看的,这会儿早翻篇了。
8% 的加密 reasoning。连那些想过、但最后没走的岔路,也一起背着。
这些东西,没有一条进了最终那次 commit。一条都没有。就算你嫌这个口径太松,只数铁定重复、过期的那部分,也有近三成是怎么算都甩不掉的死重。
表现变脆,不是因为窗口长,是因为长出来的七成,跟当前这一步无关。模型每往前走一步,都得在这 22 万里,把那 27% 真正相关的针,从七成多的旧脚印里重新认出来。
草越堆越高,针没多一根。找得慢,就慢;偶尔把草认成针,就改错地方、漏掉一条约束。
dirty context 的代价,不是它占了多少 token,而是它逼着模型在一地旧脚印里反复辨认:这一刻,我到底要的是哪一点。
我现在做的,就是把每一轮重读整个代码库,换成召回项目记忆,只刷新这次真正改动的文件。让 context 不再是一条只进不出、最后被 compaction 一刀砍掉的单向车道。
那就别再每轮从头读一遍
七节拆下来,病根就一句:模型没有记忆,所以每一轮都把整段历史当 input 重发。脚印越堆越厚,针越来越难找。
解法不是更大的窗口,也不是把日志压得更狠——那只是把同一堆脚印塞得更密。解法是:把“状态”从每轮重读的流水账,变成一份能带着走的记忆。
这就是我在做 Echo 的原因。
Echo 是一个 MCP。接到 Codex、Claude Code、Cursor、ChatGPT 上,它替你记住这个项目真正要紧的东西——做过的决定、定下的约束、改过哪些文件、上次卡在哪——存成可检索、可过期、跨工具通用的记忆。下一轮,它只把这一步真正要用的递给模型,而不是把 22 万的旧脚印再背一遍。换个工具接着干,记忆跟着走,不用重新解释一遍。
但你不用信我这一篇。量你自己的。
装上 Echo MCP,指向你自己的 session——几分钟,你就有了属于你自己的那张表:你的窗口多大、几成是 input、几成是像 page.jsx 那样被读了几十遍的脚印、你为“重读”付了多少钱。
我把我的 99.7%、我的七成脚印,都摊开给你看了。现在轮到你——看看你自己的,有多脏。