How dirty is your context window?
If you’re a heavy Codex or Claude Code user, you know the feeling: rename a heading, nudge a button, and a few hundred thousand tokens go up in smoke. By the end of this piece you’ll see the full receipt — why over 99% of your tokens go to input, and how the same old context gets re-fed round after round.
99.7% of the bill goes to input
What first made me take context-window waste seriously was a Reddit post by karmendra_choudhary. The author had tracked 100 million tokens of their own Claude Code usage — and 99.4% of it was input. Meaning: almost none of that money went to the model writing code. It went to re-feeding old context, every single turn.
I didn’t quite buy it, so I grabbed one of my own Codex coding sessions and took it apart. The result was even starker: 99.7% input. Out of that session’s 10.9 million tokens, only 25.8K were actual output — less than 0.3%.
Then I went back through my history and pulled the 69 Codex conversations I could still account for. 1.70 billion tokens in total. At API list pricing, that’s roughly $1,470. And of that money, 99.7% went to input — most of it billed at the cached-input rate for old context. The real output was worth about $167.
This isn’t “one conversation got expensive.” This is you, every day, waiting for the model to swallow a giant heap of history before it writes anything.
So the real question is this: is all that input actually doing anything? Or is it stretching your wait, diluting the model’s judgment, and dragging down your coding agent’s performance?
Talk is cheap. Show me the commit.
In Codex, a working session is essentially a conversation aimed at getting the code right and landing a single code commit. On a team you can think of it as a PR: the code has to reach a checkable, mergeable, traceable outcome.
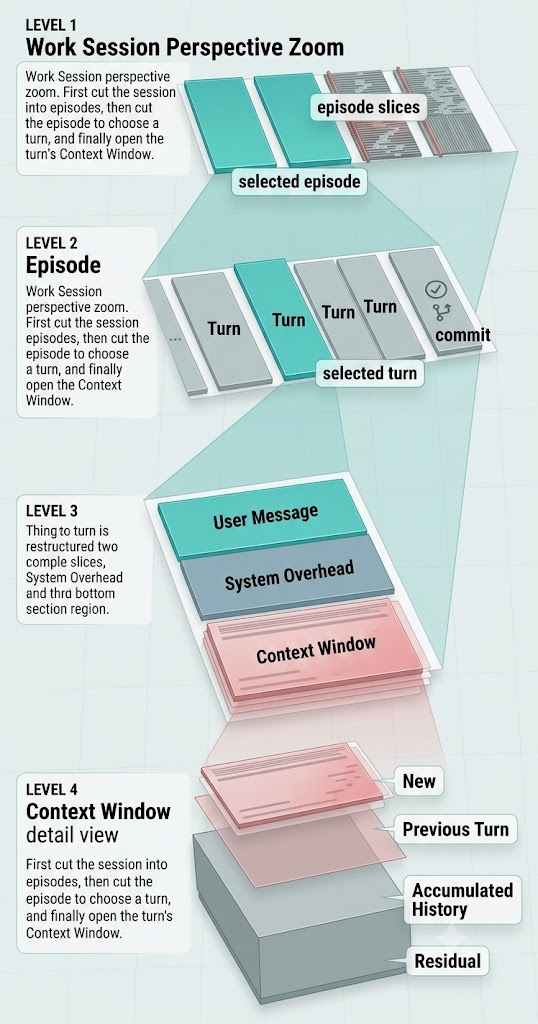
So the commit is the most natural boundary. Only once code is committed does the work leading up to it count as a finished, meaningful unit.
But a commit usually doesn’t land in a single turn. It typically takes several. I describe what I want; the agent reads files, edits code; I correct it; it edits again. Finally, it lands the commit. We call this short stretch an episode.
A working session can hold multiple episodes. How many you run depends on your habits: some people do one thing per session, others keep going for several commits in a row.
Every turn inside an episode also carries its own context window. System prompts, prior dialogue, files it read, tool-call history, tool outputs, the code it just modified — all of it lives inside that window.
Once we break it apart this way, we can look at it from a different angle: what context does one commit actually need, and how much useless old baggage is it being forced to drag along?
An ordinary task is the one that exposes the problem
Day to day I’m a heavy user of Codex, Claude Code, and OpenClaw. Nothing mystical, no megaprojects — mostly web and apps: pages, components, animations, production bugs.
Just looking at Codex: from April 25 to today, I’ve accumulated 120 sessions. June alone has 69. I picked the June 2 session, not because it’s extreme, but because it’s so ordinary.
That day’s task was redoing the Echo homepage: tweaking the layout, adding a value-prop module, wiring up a mascot loading animation. The screenshot on the right is the page I was working on.
This session went 70 turns and landed 7 commits. The process was perfectly normal. I stated the goal; the agent read files, modified code, checked the result. I corrected, it adjusted, and once it was stable, the commit landed.
That’s what makes it representative: the task isn’t big, the workflow is real, the output is unremarkable. What’s not ordinary is the cost. This single homepage refresh chewed through 10.9M tokens. About 156K tokens per turn, on average. To put that into something you can feel: Moby Dick runs roughly 210K words, around 280K tokens — meaning every time I sent the agent a single sentence, it showed up dragging more than half of Moby Dick through the door with it.
Which raises the question: why does an ordinary edit have to lug around this much context? Is any of it actually necessary?
Zooming in on the last commit
So what’s actually inside a context window the size of half of Moby Dick? We don’t need to read all 70 turns. Take the three turns right before the last commit as our specimen: T65, T66, T67.
A note on the setup: the user’s goal was crystal clear. I already knew what I wanted — fix the homepage animation loading. The final commit ended up touching 5 files, with a diff of 106 lines added and 18 deleted.
But “useful” can’t mean only the files that got modified. The directly-edited files are the product; the supporting files I didn’t touch but which decide whether the change ships safely must count too: the protected route, buffer reuse, token cookies, middleware, Next packaging config, and whether v21 private resources are still kept private.
In practice that’s not how it played out. T65 had just emerged from the previous commit, already carrying a 182.1K-token context window. Then T66 ran one re-orientation loop: scanning recent related changes, searching components, checking the asset loading path, reading config, testing production behavior. It did produce a plan.
But the plan tripped over a hard constraint: one of the resources can’t simply become a plain public asset. More importantly, this wasn’t fresh information the user dropped on it at T67. The project history already contained this protection logic, and T66 itself had re-read the relevant paths and config in this same round. The problem: when it came time to synthesize the plan, that constraint never made it to top priority.
So T67 became a correction round: the user dragged the hard constraint it had just read back into focus, the AI reversed course, and switched to a loading strategy that doesn’t break the protection boundary. The following turns kept verifying the environment: are the resources still correctly protected, is production behavior consistent, are the verifications reliable. By T70, those 5 files finally landed in the commit.
So the problem isn’t “the user wasn’t clear.” The user’s goal was clear, the scope of change was small, the key constraint was in project history, and T66 had already read it. But execution still went through every motion: re-locating, drifting off plan, re-elevating the constraint, validating a second time, re-confirming the environment. Each step served its purpose once, but every one of them also stayed in the context window, layer on layer.
That’s what makes T65 through T67 so glaring: T66 jumped straight to 220.2K tokens, T67 didn’t shrink at all. Just those three turns ate 622.5K tokens. And worse — as the chart below shows — the portion actually relevant to this commit is tiny; most of the space is occupied by old records and detours.
22.9% rough signal · 77.1% old record
20.1% rough signal · 79.9% old record
27.3% rough signal · 72.7% old record
T66 and T67 exist, fundamentally, because execution had already missed once: the key constraint was re-read but never made it into the plan, so one extra round of correction, rollback, and revision got tacked on.
This matches what Chroma found in Context Rot: after controlling for task complexity, model performance degrades as input length increases[1]. Anthropic’s Effective Context Engineering defines context as a finite resource and stresses curating the tokens best suited to current reasoning, rather than filling the window[2].
So the problem exposed here isn’t only that tokens are expensive. Long context also lowers accuracy: the model spends huge effort re-reading what it already read, and can still miss the constraint that actually mattered, then make a mistake it could have avoided.
The focus shifts: the question isn’t how big the window is. The question is, of those 220K tokens, which ones actually help the commit land — and which ones are just old scenery, or worse, are burying the useful signal.
The answer is already in context — yet it goes and looks it up again
Back to T66. The task I gave was very specific: the homepage animation loads too slowly in production — find the cause, fix it. This didn’t start from zero. Earlier in the thread there were two pieces of crucial background: the v21 Rive assets had been moved from public to private, protected by a signed-token route; the slow loading had already been worked on once, including pre-download, buffer reuse, loader, and wasm preload.
Because of how Codex works, T66 didn’t start blank. The official docs say a thread contains prompts, model outputs, and tool calls; while the agent executes, it also accumulates file contents, tool output, and an ongoing record — and all of that has to fit into the next model call’s context window[3]. So before T66’s first model call, the runtime had already packed the previous thread record into the input.
The raw log confirms it: T66’s first call already carried 181,929 input tokens, before it had performed any new tool reads. The model’s first agent message was “trace back from the most recent Rive / homepage changes”; only then did it start calling git log, rg, file reads, and curl. The searches that followed weren’t the source of context — they were the execution path the model chose after receiving context.
That’s exactly where the trouble is. The context was already in the window, but the model didn’t directly inherit it as the current task state. It re-located, re-searched, re-validated — pulling protected routes, private resources, token cookies, buffer reuse, and wasm preload all over again.
The round wasn’t light: 10 reasoning items, 25 tool calls, 25 tool outputs, 9 intermediate judgment/progress messages, and finally 1 patch attempt. In order, it did seven things: reframed the task as debugging production loading; checked git status and git log; ran rg for the Rive entry; read homepage, layout, buffer reuse, and wasm preload; read tokens, middleware, protected API, and private resource config; ran curl to verify cookies, 403s, and 200s; finally synthesized a plan.
The drift happened in synthesis. T66 had already read that /api/rive/4e1d8c is cookie-protected — yet it still proposed turning homepage v21 into a public, CDN-cacheable asset. It wasn’t until T67, when I pointed out that v21 must not become plain public, that it reversed course. The error wasn’t that the context didn’t make it in. The key signal made it in — and then got buried under a whole round of debugging scenery.
That’s where every later piece of waste starts. The context was preserved — but being preserved is not the same as being correctly used. To the runtime, it’s a thread record. To this model call, it turns into a pile of evidence that needs to be re-filtered: commits to re-walk, files to re-search, intent to re-understand, protection boundaries to re-confirm.
What T66 left behind isn’t a clean conclusion either. It’s an entire stretch of debugging scenery: the files it read, the paths it searched, the commands it ran, the diffs it inspected, the hypotheses it tested, and that one off-target plan at the end. When the next turn starts, the runtime quietly assembles all of it into the input for the next model call.
By T67, what the model reads is far more than my single correction. It also has to carry the whole execution record from T66 and re-decide: what’s still relevant to this commit, what’s already overturned, and what will actively pull it off course.
The numbers make it clear. T65 came out of the previous commit at 182.1K. By T66, after that re-orientation round, the window jumped to 220.2K — +38.1K. By T67, the total didn’t come down: still 220.2K.
Three turns add up to 622.5K input tokens. Now switch to a stricter accounting: don’t double-count each round, dedupe by file + line segment. A file read twice, same segment, counts once; if T67 re-reads lines T66 already saw, all of it counts as a duplicate.
Direct changes
The final commit touched 5 files: the homepage, layout, token logic, and two self-hosted wasm runtimes.
Critical support
Another 4 supporting files have to be present: the Rive route, buffer, middleware, Next config. They don’t necessarily change, but they set the boundary.
Explicit duplication
T67 re-read 512 lines of app/page.jsx, fully inside the range T66 already read; layout overlapped by another 19 lines.
Rough proportion
Direct + critical support, after dedupe, comes to about 1,190 lines, around 9.6K tokens — roughly 1.5% of those three turns’ input.
T65 didn’t add any new useful file for this commit; it was just the state record of the previous commit. T66 dragged the scene back out. T67’s new input was tiny — it was just reminding the model of one already-read hard constraint: v21 must not be public. What actually inflated was that entire middle round of searches, validations, diffs, curls, and duplicate file snapshots.
Once you dedupe strictly, T67’s 220K-token window isn’t a clean memory — it’s the entire execution scene from T66 being dragged forward; the code that actually serves this commit is only a tiny piece inside it.
Why this is inescapable
This isn’t about one agent being badly built. It’s a consequence of how the runtime works.
Codex’s own docs are explicit: a thread holds your prompts, model outputs, and tool calls. While the agent works, it keeps accumulating file contents, tool outputs, and an ongoing record of what it has done and what it plans to do next. All of that has to be stuffed into the context window for the next model call.
Inside our 70-turn session, it mainly operates in three modes: most of the time, copy-forward + append, carrying old records into the next turn; when the window gets tight, oldest-edge truncation drops some material from the edge; once it hits a threshold, compaction rewrites a stretch of history as a summary. It’s not a memory system. It’s shuffling, truncating, and rewriting execution records under a context limit.
So the window will grow no matter what. Any episode that needs multiple rounds of file reads, searches, code edits, diff inspection, and verification will see context climb from tens of thousands of tokens to over 200K. Even if the user’s next message is one sentence, the model still has to swallow that entire execution scene first.
And growing isn’t just expensive. Chroma’s Context Rot documents a basic fact: models don’t use long context uniformly; the longer the input, the less stable the output[1]. Inside a coding agent, that means old file versions, stale diffs, command outputs, and finished searches all sit mixed together with the few lines you actually want to change right now.
The result isn’t that the model fails. The result is that accuracy starts to drift: it grabs the wrong version of a file, follows an old path, keeps going in the direction of the last search. It will still succeed — but it takes more turns, more tokens, more corrections.
It’s going to be big. And the bigger it gets, the easier it is for the one thing you actually need to look at to be buried.
Use the commit as your ruler: the useful code is a small slice
“Long” isn’t the disease. The same 220K would be fine if every line of it related to what we’re doing in this moment. The trouble is that most of it doesn’t.
The commit is the hardest ruler we have.
In the end, this commit touched 5 files and 124 lines of diff. But useful material isn’t just the final diff: route, buffer, middleware, Next config, and the location of the v21 private resource — none of those necessarily land in the commit, but they decide whether the change ships safely.
So I define “effective context” as two classes: direct product + critical support. After deduping by file and line segment, the truly effective material across T65–T67 is roughly 9.6K tokens — about 1.54% of 622.5K input. Add in two pieces of historical evidence and it climbs to 10.5K, about 1.69%.
Everything else isn’t entirely without process value, but it isn’t something the final commit needs to inherit or use as a boundary. It mostly looks like this:
- Wide searches:
rgandfindhelp the model locate entry points, but their results contain huge swaths of paths that have nothing to do with the final commit. Once the entry point is found, those results should walk off stage. - Diagnostic output:
git diff,curl, headers, statuses, directory listings — the scaffolding you used while chasing the bug. After the check is done, they keep sitting in the window. - Duplicate file snapshots: T67 re-read two segments of
app/page.jsx, 512 lines in total, all of which sat inside the range T66 had already read. The second appearance adds no new information. - Old scene from the previous commit: T65’s git status, diff, and push output mattered for the previous stretch of work. Coming into this animation fix, they’re just history being carried forward.
- The wrong approach itself: T66 produced a plan that would have pushed v21 to public. T67 had to take it back first; that drift then became the scene the next turn had to carry.
All of these helped the model take a step forward. None of them have earned the right to stay forever in “current valid state.” Direct product and critical support should remain; search scaffolding, duplicate snapshots, and aborted directions should be demoted, folded, or dropped once they’ve done their job.
Instability isn’t coming from window length. It’s coming from the window holding too much material that should have exited the stage after one use. Old records keep stacking up, the few lines that actually need to change don’t multiply, and every step forward the model takes is one more round of having to re-identify those 1,190 truly relevant lines of code.
This is context signal-to-noise. Under our three-turn dedupe accounting, the true signal is only 1.54%. The cost of dirty context isn’t just the tokens and time it consumes — it’s how it drowns the useful signal under context noise. Every step forward, the model has a harder time finding what actually matters. Of course performance drops.
The things you think solve this — mostly don’t
Reading this far, you might be thinking: I’ve already got a tool for this. Hold on. Most of those “tools” never touch the root cause.
AGENTS.md / CLAUDE.md. Static instructions written at the very front. They can tell the agent “how to behave,” but they don’t expire, they don’t auto-clean after a commit, and they certainly don’t manage the old files, old diffs, and old searches that pile into the window every turn. The rules get longer; the old records don’t shrink.
Note-style memory (stuffing key points into project markdown, cloud memory). Right direction, wrong execution: you’re adding more to the window. Adding content isn’t the same as reducing dirt — the useless old records weren’t cleared, you just stacked a new layer on top.
Enterprise KM / RAG / vector databases. These solve “fetching information from outside,” not “the same scene appearing over and over in an execution transcript.” They can recall a document for you — but those 512 duplicate lines of app/page.jsx are still right there in the window.
Bigger windows, harsher compression. The previous section already gave this away: that just packs the same useless old records denser and more evenly on top of the few lines that actually need to change. The arrangement got tidier; the number of lines that need to change didn’t budge.
This isn’t one tool being misconfigured. The mistake is treating execution history as memory — so whichever tool you swap in, the dirt stays.
Measure your own context signal-to-noise
I laid my own books out: 99.7% input; last three turns 622.5K tokens; after deduping, truly effective signal only about 1.5%.
If I pulled the average context signal-to-noise across my 1.70 billion tokens up to 50%, the same effective signal would only need around 51M tokens — saving roughly 1.65 billion tokens. Scaling time proportionally across these sessions, that’s about 44 hours, close to 5.5 eight-hour workdays.
Your turn. We open-sourced the context signal-to-noise algorithm, dedupe rules, and analysis method used in this piece. Hook up Echo MCP, point it at your own Codex, Claude Code, or Cursor sessions, and you can run your own AI context noise report.
References
- Chroma Research, Context Rot: How Increasing Input Tokens Impacts LLM Performance.
- Anthropic Engineering, Effective Context Engineering for AI Agents.
- OpenAI, Codex Manual, sections on prompting, thread model, and context.