Context Window Analysis · Agentic Coding · Updated Jun 26, 2026
How dirty is your context window?
Over 99% of your token spend is input — because your context window is filthy. Old context, repeated searches, expired content, all of it re-fed every single turn.
99.7% are input
I tracked 100M tokens of Coding with Claude Code - 99.4% of my AI coding tokens were input. If we fix that, we unlock real speed.
by u/karmendra_choudhary in r/ClaudeAI
One day a Reddit post crossed my feed. The author had broken down their own spend inside Claude Code: out of a hundred million tokens, 99.4% was input. Meaning almost none of the money went to the model writing code. It went to feeding the context back in.
I didn't really buy it. So I grabbed one of my own Codex work conversations, a real coding session, and took its tokens apart.
The result was even higher than his: this session burned 10.9M tokens, 99.7% input, with only 25.8K of output actually written out.
I assumed it was a one-off, so I pulled more. Across all the Codex history I can still account for, there are 69 sessions, 1.70B tokens total, roughly $1.47K at API prices. 99.7% of it is input, and 94% of that input is cached input, the old context re-sent every single turn.
The money tells the same story. These Codex conversations cost about $1.47K in total, and the output was worth only about $167 of it. Most of the money went to reading input.
This is not normal. So I ran a deeper analysis, and I'm sharing it here. TLDR: our context windows are all filthy. If your agent feels expensive, slow, or keeps turning a simple task into a complicated mess, it's most likely because its context window is filthy.
2. Which session I picked to analyze
First, the sample. I'm a developer who uses Codex, Claude Code, and OpenClaw at the same time. Day to day I mostly do website development, Chrome extensions, some app interfaces, and product experiments around EchoMemory.
The Codex history I can currently account for is 69 sessions, 1.70B tokens in total. It isn't a benchmark I ran in one go. It's agent conversations from my actual work: edit a page, tweak an interaction, wire up an extension, run checks, commit, then move on to the next round.
I picked one session in particular to dissect. It's not the biggest or most extreme one, but it's very representative: a front-end page development task, 70 turns, 7 commits, landing on a diff across a few files. The target is typical too: not training a model, not migrating a database, just building a real product page, smoothing it out, and fixing it until it can ship.
Why is it good to analyze? Because it sits right between “ordinary” and “complex.” It's not a one-line fix, and it's not a months-long rewrite. It has continuous context, several local edits, commit checkpoints, and the full loop of reading files, searching, verifying, and fixing mistakes over and over.
This session burned 10.9M tokens, 99.7% of it input, with only 25.8K of output actually written out. In other words, one ordinary product page turned into tens of millions of tokens of context throughput.
More to the point, the cost didn't go to “writing more code.” It went to rebuilding the worksite over and over. To find something it had just looked at, my agent read the code again and again, searched again and again. The times it actually “remembered what it learned last time” were far fewer.
It doesn't remember. It re-reads.
3. How we take a working session apart
Next I need to define the unit of analysis. A working session isn't one solid block. It has smaller structure inside: a session contains episodes, an episode contains turns, and every turn carries a context window.
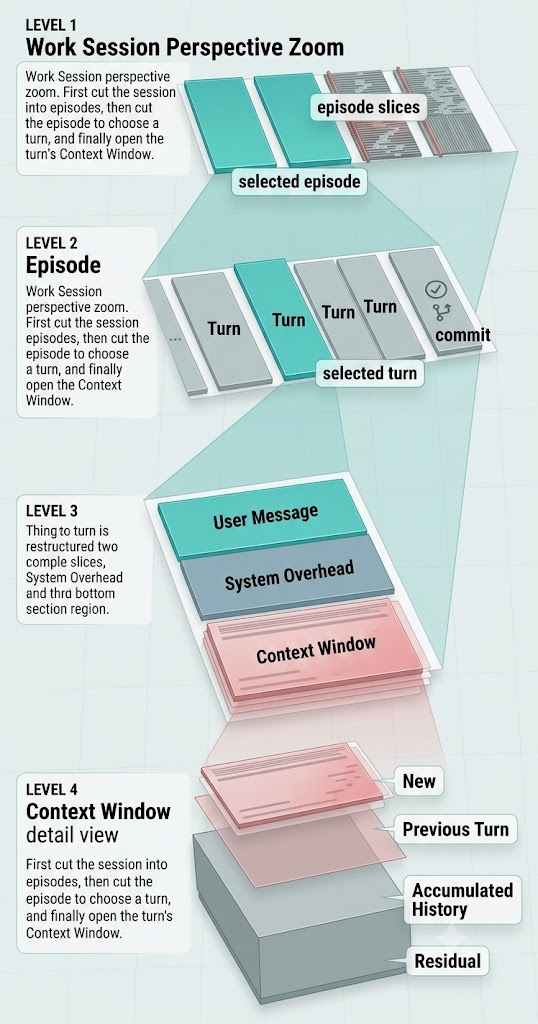
I call the work leading up to one commit an episode. Because a commit is a hard boundary: the code actually landed, which means that stretch finished at least one meaningful task.
Under this definition, “useful context” isn't everything stuffed into the window. It's the part that actually shaped the commit. It can be instructions, design principles, background judgment, or some code file. As long as it helped the commit, it's useful.
Flip it around: things that were read but never used, searched but never moved the task forward, expired but still sitting in the window, none of that counts as useful context. It just gets dragged into the turn, taking up tokens, taking up attention, adding noise.
So I look at the whole session first, then cut down to an episode, then to each turn inside the episode, and finally take apart each turn's context window. Only then can you see what a task actually needs, and how much old baggage it's forced to carry.
4. Zooming into one episode: turns 65 to 67
Now into a concrete context window. The episode I'm watching is the last one in this session. It starts from a set of Rive production loading fixes and ends as the commit Fix protected Rive production loading.
What this episode has to solve is very specific: the protected Rive v21 asset must not be treated as an ordinary public asset. Which means the agent needs to understand the existing asset-protection rules, the production loading path, the current page code, and the design constraints I'd hammered on repeatedly earlier.
I pulled three adjacent turns to look at: turn 65 locates the problem, turn 66 prepares the fix, turn 67 is me correcting its direction. All three are in the same episode, and all three serve the same commit in the end.
Turn 67 makes the point best. I typed one line: You shouldn't have turned that protected v21 into a plain public one.
That turn's window is 220.2K tokens. The new content that belongs to this turn is only 4.8K, just 2.2%. The other 97.8% is old history re-sent verbatim from cache. To catch this one sentence, the model has to walk through that other 97.8% from the top first.
Of those 220.2K, more than half could have been left out:
Must keep, 27%
System overhead 6.3%, plus still-living product code 20.9%.
Could drop, 73%
Re-searching 45%, duplicate reads 10%, stale dead content 18%.
Where the feeling comes from
That nagging “why is it digging around again” feeling I always get? It comes from this 45%.
5. It's already in context, yet it keeps redoing it
The main file, page.jsx, I had it edit 70 times. Every version gets read back in, 122K tokens in aggregate. And most of what got read in was folded away wholesale by compaction before the next few turns ever used it.
In this session, compaction fired 5 times. The window swells to the limit, then crushes a whole stretch of history into a one-line summary and reopens a clean window.
Paid for. Took up space. Read once. Thrown away.
6. Why it has to be this way
Shrink the task until it can't get any simpler, change one line, delete one sentence. It still triggers a re-read of over two hundred thousand tokens.
The problem isn't some complex task. It's the mechanism itself.
LLMs are stateless; context only goes in, never out. At turn N the window is about N * Δ, so cumulative input is about Δ * N² / 2, quadratic. Output is about c * N, linear. Pile on enough turns and the ratio has to blow past 99%.
This isn't waste. It's geometry.
7. So put down what it can't hold
The problem isn't that AI isn't smart enough, or that the window isn't big enough. It's that it has no working memory, so it's stuck using its execution history as memory.
If it didn't move a commit forward, it wasn't useful. Anything a turn burns through that brought nothing closer to landing is just noise.
Duplicates can be flushed. The seventh read of the same file with no new information should be cleared out.
Every turn can slim down a lot. Strip out what didn't move a commit, strip out the duplicates, and that 220,212 isn't shaving off loose change, it's cutting more than half.
What I'm building now is exactly this: replace re-reading the entire codebase every turn with recalling project memory and refreshing only the files that actually changed this time. So context stops being a one-way street that only takes on more and finally gets cut down in one stroke by compaction.
I'm not slow. I just can't put anything down.
Put down what you couldn't put down, and AI can finally get fast. What Echo is built to do is stop the agent from faking memory with its whole execution history, and actually know which context to keep and which to let go.