你的 context window,到底有多脏?
如果你是 Codex 或 Claude Code 的重度用户,你应该有过这种感觉:只是改个标题、挪个按钮,几十万 token 就烧掉了。读完这篇,你会看清这笔账:为什么 99% 以上的 token 都花在 input,旧上下文又是怎么一轮轮被重新喂进去的。
99.7% 的钱花在 input 上
我第一次认真意识到 context window 有多浪费,是因为 Reddit 用户 karmendra_choudhary 的一条帖子。作者统计了自己在 Claude Code 里的一亿 token 消耗:99.4% 都是 input。也就是说,钱大部分不是花在模型写代码上,而是花在每一轮把旧上下文重新喂进去。
我一开始不太信,于是抓了一条自己的 Codex coding session 来拆。结果更夸张:99.7% 是 input,在这条 session 的 10.9M token 消耗里,真正写出去的 output 只有 25.8K,不到 0.3%。
后来我看了 Codex 历史里能核对的 69 个对话,总共是 17 亿 token 消耗。按照模型 API 价格估算,大概是 1470 美金。在这笔钱里,竟然 99.7% 都是 input;其中大部分还是按 cached input 计价的旧上下文。真正 output 只值约 167 美金。
这就不是“某一次对话很贵”了,而是你每天都在等模型先吞下一大坨历史,再写一点东西。
所以真正的问题是:这么多 input 真的有用吗?还是它正在拖慢等待、稀释判断、拉低 coding agent 的 performance?
不以 code commit / PR 为目的的代码修改,都是耍流氓
在 Codex 里,一个 working session 本质上就是一串为了把代码改对、最后落成一次 code commit 的对话。团队里你也可以把它理解成 PR:代码必须落到一个可检查、可合并、可追踪的结果上。
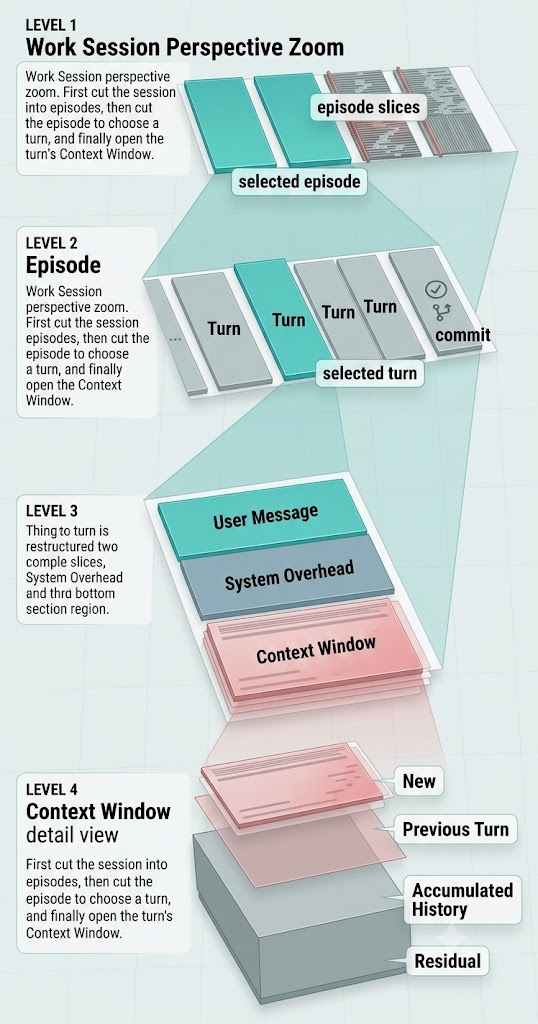
所以 commit 是最自然的边界。只有代码被 commit 了,才说明前面那段工作真的完成了一个有意义的小任务。
但一个 commit 往往不是一轮做完的。它通常需要好几个 turn:我提要求,它读文件,它改代码,我纠正,它再改,最后 commit。我们把这一小段叫一个 episode。
一个 working session 里可以有多个 episode。多少取决于你的习惯:有人一个 session 只做一件事,有人一路聊下去,做完好几个 commit。
episode 里的每一个 turn,又都有自己的 context window。系统提示、前面的对话、读过的文件、工具调用历史、工具输出结果、刚刚改过的代码,全都在这个上下文窗口里。
这样拆开以后,我们就能换一个视角看进去:一次 commit 到底需要哪些 context,又被迫背上了多少已经没用的旧东西。
普通任务,最能暴露问题
我平时重度用 Codex、Claude Code 和 OpenClaw。做的也不是玄学大工程,主要就是网页和应用:页面、组件、动画、线上 bug。
只看 Codex,从 4 月 25 号到现在,我攒了 120 个 session,光 6 月就有 69 个。我挑了 6 月 2 号那条,不是因为它极端,而是因为它太普通。
那天的活儿是重做 Echo 官网首页:调排版、补卖点模块、接一个吉祥物 loading 动画。右边图片里,就是我当时在做的页面。
这条 session 走了 70 个 turn,最后落了 7 次 commit。过程也很普通:我说目标,agent 读文件、改代码、看效果;我再纠正,它再改,能落地就 commit。
所以它有代表性:任务不大,流程真实,产物也不重。真正不普通的是代价:这样一个首页改动,最后吞了 10.9M token。平均每轮约 15.6 万 token。按《红楼梦》约 75 万字、约 40 万 token 粗算,相当于每说一句话,模型都先背着几乎半部《红楼梦》进来。
那问题来了:为什么一次普通修改,要背这么多上下文?这些东西,真的都有必要吗?
把镜头推到最后一次 commit
那这半部《红楼梦》大小的 context window 里,到底装了什么?不用把 70 轮全读完,我们拿最后一次 commit 前的三轮举例:T65、T66、T67。
先把研究环境说清楚:这次用户目标很明确。我已经知道自己要什么,就是把首页动画加载修好。最后真正落到 commit 里的,是 5 个文件,代码 diff 是 106 行新增、18 行删除。
但“有用”不能只看最后改了哪些文件。直接要改的是产物文件;不直接改、但决定能不能安全落地的辅助文件,也必须算进去:保护 route、buffer 复用、token cookie、中间件、Next 打包配置,以及 v21 私有资源是不是还留在 private。
真实执行不是这样。T65 刚从上一个 commit 出来,已经带着 182.1K token 的 context window。然后 T66 先做了一轮重定位:翻最近的相关改动,搜组件,查资源加载路径,看配置,测 production 表现。最后它确实给出了一个方案。
但这个方案踩到了一个硬约束:有一份资源不能直接变成普通 public。更关键的是,这不是用户在 T67 才告诉它的新信息。项目历史里已经有过这条保护逻辑,T66 自己也在这一轮重新读到了相关路径和配置。问题是,到真正出方案时,这个约束没有被放到最高优先级。
所以 T67 变成了一轮纠偏:用户把它刚刚读过的硬约束重新拉回焦点,AI 撤回错误方向,换成不破坏保护边界的加载方案。后面几轮继续做环境确认:资源是不是被正确保护、production 行为是不是一致、验证结果是不是可靠。到 T70,这 5 个文件才 commit。
所以问题不是“用户没说清楚”。用户目标已经清楚,修改范围也很小,关键约束在项目历史里,T66 也已经读到。但执行过程还是出现了重定位、方案偏航、约束重拉、二次验证、环境确认。每一步都有用过一次的价值,可它们也一层层留在 context window 里。
这就是 T65 到 T67 最刺眼的地方:T66 直接涨到 220.2K token,T67 没有变小。光这三轮就已经吃掉 622.5K token。更麻烦的是,下面这张图里会看到:真正和这次 commit 相关的部分很少,大量空间都被旧记录和绕路占着。
22.9% rough signal · 77.1% old record
20.1% rough signal · 79.9% old record
27.3% rough signal · 72.7% old record
T66 和 T67 之所以出现,本质上就是因为执行现场已经错过了一次:关键约束被重新读回来,却没有真正压住方案,于是又多出一轮纠偏、回滚和重改。
这和 Chroma 在 Context Rot 里观察到的现象一致:他们在控制任务复杂度后发现,model performance degrades as input length increases[1]。Anthropic 的 Effective Context Engineering 也把 context 定义成有限资源,强调要维护最适合当前推理的那组 tokens,而不是把窗口塞满[2]。
所以这里暴露的问题不只是 token 贵。过长的上下文还会降低准确度:模型花大量成本读已经读过的内容,最后依然可能漏掉真正重要的约束,然后犯一个本来可以避免的错。
焦点变了:问题不再是窗口有多大,而是这 22 万 token 里,哪些真的有用、能帮最后 commit 落地;哪些只是旧现场,甚至会淹没有用信号。
答案已经在 context 里,它还是又查了一遍
回到 T66。我给的任务很具体:首页动画在 production 加载太慢,找原因并修掉。这个问题不是从零开始。前面的 thread 里已经有两条关键背景:v21 Rive 资源已经从 public 挪到 private,通过 signed-token route 保护;加载慢也已经被处理过一轮,包括提前下载、buffer 复用、loader 和 wasm preload。
Codex 的工作方式决定了,T66 不是空白开始。官方文档说,一个 thread 包含 prompt、model outputs 和 tool calls;agent 执行时还会收集 file contents、tool output 和 ongoing record;这些信息都要放进模型的 context window[3]。所以 T66 第一次 model call 之前,runtime 已经把上一轮 thread record 组装进 input。
原始 log 对得上:T66 第一次调用已经带着 181,929 input tokens,而那时它还没有做新的工具读取。模型的第一条 agent message 是“从最近 Rive / 首页改动倒查”,随后才调用 git log、rg、文件读取和 curl。后面的搜索不是 context 的来源,而是模型拿到 context 之后选择的执行路径。
问题就在这里:context 已经在窗口里,但模型没有把它直接当成当前任务的有效状态继承。它重新定位、重新搜索、重新验证,把保护路由、私有资源、token cookie、buffer 复用、wasm preload 又拉了一遍。
这一轮并不轻:10 个 reasoning item、25 次 tool call、25 个 tool output、9 条中间判断/进度消息,最后还有 1 次 patch 尝试。按顺序看,它做了七件事:把任务转成 production loading debug;查 git status 和 git log;用 rg 搜 Rive 入口;读首页、layout、buffer 复用和 wasm preload;读 token、中间件、保护 API 和 private resource 配置;用 curl 验证 cookie、403 和 200;最后合成方案。
偏差发生在合成方案时。T66 已经读到 /api/rive/4e1d8c 受 cookie 保护,却仍然提出把 homepage v21 改成 public CDN-cacheable asset。到 T67,我指出 v21 不能变成普通 public,它才撤回方向。错误不是“context 没进来”,而是关键信号进来了,又被一整轮 debug 现场埋掉了。
这就是后面所有浪费的起点。context 被保留了,但保留不等于被正确使用。对 runtime 来说,它是一段 thread record;对这次模型调用来说,它变成了一堆需要重新筛选的证据:commit 要重新翻,文件要重新搜,意图要重新理解,保护边界要重新确认。
T66 留下来的也不是一个干净结论,而是一整段 debug 现场:它读过的文件、搜过的路径、跑过的命令、看过的 diff、验证过的假设,以及最后那个偏航的方案。下一轮开始时,runtime 会把这些东西继续组装进 model-call input。
到了 T67,模型读到的远不止我一句纠偏。它还要带着 T66 这一整轮执行记录,重新判断:什么还和这次 commit 有关,什么已经翻篇,什么反而会把它带偏。
数字上很直观。T65 刚从上一个 commit 出来,窗口是 182.1K。到 T66,因为这一轮重新定位,窗口跳到 220.2K,多出来 38.1K。到 T67,总量没有降,还是 220.2K。
三轮加起来,是 622.5K input tokens。现在换一个更严格的算法:不按每轮重复累加,只按“文件 + 行段”去重。一个文件读了两次,同一段只算一次;T67 再读到 T66 已经读过的行,全部算重复。
直接改动
最终 commit 改了 5 个文件:首页、layout、token 逻辑,以及两个自托管 wasm runtime。
关键辅助
另有 4 个辅助文件必须在场:Rive route、buffer、middleware、Next 配置。它们不一定改,但决定边界。
明确重复
T67 又读了 512 行 app/page.jsx,全部落在 T66 已经读过的区间里;layout 也重复了 19 行。
粗算比例
直接改动 + 关键辅助,去重后约 1,190 行、9.6K token,只占三轮 input 的约 1.5%。
T65 对这次 commit 没有新增有用文件,它只是上一个 commit 的状态记录。T66 把现场重新拉出来。T67 的新输入很小,只是在提醒一条已经读到的硬约束:v21 不能 public。真正膨胀的,是中间那整轮搜索、验证、diff、curl 和重复文件快照。
严格去重以后,T67 的 22 万 token 不是一份干净记忆,而是一整段工作现场;真正能直接服务这次 commit 的代码,只是里面很小的一块。
为什么每次都躲不掉
这不是某个 agent 写得差,而是 runtime 的工作方式决定的。
Codex 官方文档里说得很直:一个 thread 里会有你的 prompt、model outputs、tool calls。agent 工作时,还会继续收集 file contents、tool output,以及它做过什么、接下来要做什么的 ongoing record。所有这些东西,都必须塞进下一次 model call 的 context window。
在我们的 70-turn session 里,它主要有三种模式:多数时候 copy-forward + append,把旧记录带到下一轮;窗口吃紧时做 oldest-edge truncation,从边缘丢掉一部分;撑到阈值时触发 compaction,把一段历史改写成摘要。它不是记忆系统,只是在上下文限制里搬运、截断、改写执行记录。
所以窗口怎么都会大。只要一个 episode 需要多轮文件读取、搜索、改代码、看 diff、跑验证,context 就会从几万涨到二十多万 token。哪怕最后用户只补一句话,模型也要先吞下这整段工作现场。
更麻烦的是,变大不只是贵。Chroma 那篇 Context Rot 里讲过一个基本现象:模型并不会均匀地使用长上下文,输入越长,表现越不稳定[1]。放到 coding agent 里,就是旧文件版本、过期 diff、命令输出、翻完没用的搜索结果会和这一刻真正要改的那点东西混在一起。
结果不是模型一定失败,而是准确度开始飘:它更容易抓错文件版本、照着旧路径走、顺着上一次搜索的方向继续找。最后还是能成功,但要更多 turn、更多 token、更多纠正。
它注定很大,而且越大,真正该看的那一点越容易被埋掉。
拿 commit 当尺子:有用代码只剩很小一块
“长”本身不是病根。同样是 22 万,如果每一条都跟这一刻要做的事相关,它不会乱。问题是,大多数都不相关。
commit 是最硬的尺子。
这次 commit 最后改了 5 个文件、124 行 diff。但有用材料不只等于最终 diff:route、buffer、middleware、Next 配置和 v21 私有资源位置,虽然不一定进 commit,也决定这次修改能不能安全落地。
所以我把“有效 context”定义成两类:直接产物 + 关键辅助。按文件和行段去重后,T65 到 T67 三轮里真正有效的大约是 9.6K token,只占 622.5K input 的 1.54%。把两段历史证据也算进去,也只有 10.5K,约 1.69%。
剩下的,不是完全没有过程价值,但它们不是最终 commit 需要继承的产物或边界。主要长这样:
- 宽搜索:
rg、find帮模型定位入口,但搜索结果里大量路径跟最后 commit 无关。入口找到以后,这些结果就该退场。 - 诊断输出:
git diff、curl、headers、status、目录列表,都是查 bug 时的脚手架。查完以后,它们还继续留在窗口里。 - 重复文件快照:T67 重新读了
app/page.jsx两段,共 512 行,已经完整包含在 T66 读过的区间里。第二次出现,不再增加信息。 - 上一个 commit 的旧现场:T65 的 git 状态、diff、push 输出,对上一段工作有意义;进入这次动画修复时,只是被继续携带的历史。
- 错误方案本身:T66 生成过一个会把 v21 推向 public 的方案。T67 必须先撤掉它,这个偏航过程也成了下一轮要背的现场。
这些东西都帮过模型走到下一步,但没有资格无限期留在“当前有效状态”里。直接产物和关键辅助应该留下;搜索脚手架、重复快照、偏航方案,用完就该降权、折叠、丢掉。
表现不稳,不是因为窗口长,而是因为窗口里混着太多用过一次就该退场的材料。旧记录越堆越多,真正要改的那几行一行没多;模型每往前走一步,都要重新认出那 1,190 行真正相关的代码。
这就是 context 信噪比的问题:按这三轮的去重口径,真正信号只有 1.54%。dirty context 的代价,不只是它占了多少 token 和时间,而是它让有效信号被上下文噪音淹没,模型越来越难找到真正该看的东西,效果当然会变差。
你以为能解决这件事的东西,大多没在解决
看到这你可能会想:这我早有招了。但先别急——多数“招”,根本没碰到病根。
AGENTS.md / CLAUDE.md。它是一段写死在最前面的静态指令。它能告诉 agent“该怎么做”,但它不会过期、不会随着 commit 自动清掉,更管不了运行时一轮轮堆进窗口的旧文件、旧 diff、旧搜索。规则越写越长,旧记录一点没少。
写笔记式的 memory(往项目 markdown、cloud memory 里堆要点)。方向是对的,但做法是在往窗口里再加东西。加内容 ≠ 减脏:没用的旧记录没被收走,你只是又压了一层新的上去。
企业 KM / RAG / 向量库。它解决的是“从外部把资料找回来”,不是“执行 transcript 里同一段现场被反复携带”。它能帮你召回一份文档,可 app/page.jsx 里那 512 行重复快照还是会留在窗口里。
更大的窗口、更狠的压缩。第六节已经说穿了:那只是把同一堆没用的旧记录塞得更密、更均匀地盖住真正要改的那几行。装得更整齐了,要改的那几行一行没多。
这不是某个工具配错了。是“把执行历史当记忆”这件事本身错了——所以你换哪个工具,都一样脏。
去测你的 context 信噪比
我把自己的账摊开了:99.7% 是 input,最后三轮 622.5K token,去重后真正有效的信号只有 1.5% 左右。
如果把我这 1.70B token 的平均 context 信噪比拉到 50%,同样的有效信号只需要约 51M token,能少烧约 16.5 亿 token。按这批 session 的耗时同比例估算,大约能省 44 小时,接近 5.5 个 8 小时工作日。
现在轮到你。我们把这篇文章用到的 context 信噪比算法、去重口径和分析方法都开源了。接上 Echo MCP,指向你自己的 Codex、Claude Code 或 Cursor session,就能跑一份你的 AI context 噪音报告。
References
- Chroma Research, Context Rot: How Increasing Input Tokens Impacts LLM Performance.
- Anthropic Engineering, Effective Context Engineering for AI Agents.
- OpenAI, Codex Manual, sections on prompting, thread model, and context.